Справочная служба
Назначение справочной службы
Подобно большой организации, большая компьютерная сеть нуждается в хранении и удобном доступе и как можно более полной справочной информации о самой себе. Решение многих задач в сети опирается на информацию о пользователях сети — их именах, применяемых для логического входа в систему, паролях, правах доступа к ресурсам сети, а также на информацию о ресурсах и компонентах сети — серверах, клиентских компьютерах, маршрутизаторах, шлюзах, томах файловых систем, принтерах и т. п. К числу таких таких задач относятся аутентификация и авторизация.
Результатом развития систем хранения справочной информации стало появление в сетевых ОС специальной подсистемы — справочной службы.
Справочная служба (directory services[1]), называемая также службой каталогов, имеет основной целью хранение информации, относящейся к сети, в которой эта служба установлена, с тем, чтобы предоставлять эту информацию по запросам всем пользователям и приложениям, имеющим права на доступ к этим данным.
В некоторых случаях справочная служба может быть использована и для хранения информации, не связанной с функционированием сети. Например, она может включать персональные данные служащих, такие как фамилия, имя отчество, должность, заработная плата, домашний адрес, телефон, дата рождения и т. п. Или содержать технические характеристики и данные о наличии оборудования (не обязательно сетевого) в разных подразделениях предприятия. Важно, чтобы характер этих данных совпадал с характером справочной информации, для хранения которой предназначена справочная служба, а именно данные должны быть потенциально полезными для потребителей в пределах всей сети, меняться относительно редко и в небольших масштабах.
Справочная служба хранит информацию обо всех пользователях и ресурсах сети в виде унифицированных объектов, снабженных определенными атрибутами, а также отражает связи хранимых объектов, такие как принадлежность пользователей к определенной группе, права доступа пользователей к компьютерам и разделяемым ресурсам, вхождение нескольких узлов в одну подсеть, коммуникационные связи между подсетями, производственная принадлежность серверов и т. д.
Сетевая служба регулирует взаимодействие между сетевыми объектами, предоставляя доступ к информации в соответствии с заданными в ее базе данных правами доступа для разных типов клиентов этой службы. Клиентами справочной службы являются администраторы, пользователи, приложения, сетевые службы и сетевые устройства.
ПРИМЕЧАНИЕ. Альтернативой единой справочной службе сети является применение нескольких автономных справочных служб узкого назначения: одной — для аутентификации, другой — для управления сетью, третей — для разрешения имен компьютеров и т. д. Однако в крупной сети такой подход оказывается неэффективным. Даже если каждая из таких служб хорошо организована и сочетает централизованный интерфейс с распределенной базой данных, большое число справочных служб приводит к дублированию информации, усложняет администрирование и управление сетью. Например, до 2000 года в операционной системе Windows NT компании Microsoft, имелось, по крайней мере, пять различных типов справочных баз данных. Главный справочник домена (NT Domain Directory Service) хранил информацию о пользователях, требуемую для их логического входа в сеть. Данные о тех же пользователях могли содержаться и в другом справочнике, используемом электронной почтой Microsoft Mail. Еще три базы данных поддерживали разрешение адресов: служба WINS устанавливала соответствие Netbios-имен IP-адресам, справочник DNS — соответствие доменных имен IP-адресам, справочник протокола DHCP служил для автоматического назначения IP-адресов компьютерам сети. Очевидно, что такое разнообразие справочных служб усложняло жизнь администратора и приводило к дополнительным ошибкам, например когда учетные данные одного и того же пользователя нужно было ввести в несколько баз данных. Поэтому в сменивших Windows NT операционных системах на смену всем этим разрозненным справочным службам пришла интегрированная с системой DNS распределенная справочная служба Active Directory, способная хранить и поддерживать всю справочную информацию о системе. Далее в главе хх мы подробно рассмотрим работу этой справочной службы.
Архитектура справочной службы
Для типичной справочной службы характерно использование модели клиент-сервер: выделенные серверы хранят базу справочной информации, которой пользуются клиенты справочной службы, передавая серверам по сети соответствующие запросы.
В соответствии с выбранной архитектурой различают следующие типы справочной службы:
- децентрализованная;
- централизованная;
- распределенная.
Децентрализованная модель была характерна для первых реализаций справочных служб (тогда для их обозначения еще не использовался данный термин). На рисунке 5.4 показаны 9 компьютеров сети, каждый из которых оснащен собственной справочной службой, работающей независимо от остальных компьютеров сети; информационные запросы, порожденные на каком-либо компьютере, касаются ресурсов и пользователей, связанных с этим компьютером и обрабатываются на нем же.
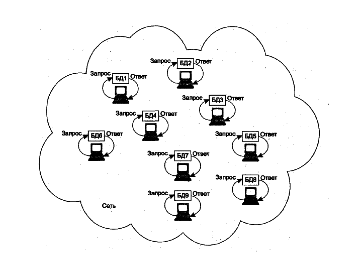
Рис. 5.4. Схема децентрализованной справочной службы
Децентрализованный подход в большой сети приводит к дублированию значительного объема справочных данных, а также к недопустимо большим затратам на администрирование. Последний недостаток отчасти смягчается тем обстоятельством, что децентрализованная справочная служба позволяет легко разделить работу по администрированию между несколькими специалистами.
Централизованная модель является естественной альтернативой децентрализованной модели. В соответствии с этой моделью вся справочная информация о сети и пользователях хранится и обрабатывается на одном компьютере.

Рис. 5.5. Схема централизованной справочной службы
На рис. 5.5 показан сервер справочной службы, обслуживающий центральную базу данных, которая объединяет справочную информацию БД1 – БД9, относящуюся к каждому из компьютеров сети. Клиентские компоненты справочной службы установлены на всех остальных компьютерах. Используя клиентскую программу, каждый пользователь и приложение, работающие на некотором компьютере сети, могут сделать запрос и получить данные о ресурсах всех других компьютеров.
При этом нет необходимости в дублировании информации. Вместо того чтобы заводить для пользователей учетные записи на тех компьютерах, на которых каждый из них работает, администратор создает и поддерживает единую базу данных для всех пользователей сети, которые обращаются к этой БД для аутентификации. Такая централизованная процедура не «привязывает» пользователя к определенному компьютеру и резко снижает избыточность и сложность ведения учетной информации.
Однако эта модель хорошо работает только в небольшой сети. Реализация справочной службы на основе единой БД, хранящейся в виде одной копии на одном из серверов сети, не подходит для большой системы в первую очередь вследствие низкой производительности и низкой надежности такого решения.
Производительность оказывается низкой из-за того, что запросы к справочной службе от всех пользователей и приложений сети поступают на единственный сервер, который при превышении определенного количества запросов перестает справлятся с их обработкой. Процедура выполнения запроса к серверу может стать неприемлемо длительной из-за задержки передачи запроса (в том числе по глобальным связям), времени пребывания запроса в очереди к серверу и времени, затраченного на поиск информации в базе данных, которое может оказаться значительным, если центральная БД имеет большой объем. Другими словами, такое решение плохо масштабируется в отношении количества обслуживаемых пользователей и разделяемых ресурсов.
Надежность также не может быть высокой в системе с единственной копией данных. Отказ аппаратуры или программного обеспечения сервера, на котором поддерживается эта база данных, приведет к параличу справочной службы в масштабах всей сети.
Смягчить недостатки централизованной модели можно резервированием, то есть поддержанием нескольких копий базы данных на разных компьютерах.
На рис. 5.6 база данных справочной службы представлена двумя идентичными экземплярами, что дает возможность повысить как ее производительность, так и надежность.

Рис. 5.6. Схема централизованной справочной службы с резервированием
За повышение надежности и производительности централизованная система с резервированием расплачивается избыточностью и сложностью поддержания нескольких копий. Кроме того, она не решает проблему плохой масштабируемости, характерную для любой централизованной модели.
Исходя из того, что в небольшой сети централизованная схема работает эффективно, одним из возможных решений могло бы быть разделение большой сети на части - домены - и реализация во всех доменах отдельных, не связанных между собой централизованных справочных служб. На рис. 5.7 показана сеть, разделенная на три домена, в каждом из которых работает собственная централизованная справочная служба. Базы данных, размещенные на серверах справочной службы в каждом домене, содержат лишь часть справочных данных сети, а именно те данные, которые относятся к ресурсам и пользователям соответствующих доменов.

Рис. 5.7. Декомпозиция справочной службы на не связанные между собой справочные службы доменов
Справочные службы доменов обладают всеми преимуществами, свойственными централизованным системам, а главный недостаток централизованных систем — плохая масштабируемость — преодолевается разделением сети на домены. Действительно, хотя увеличение размера сети и ведет к росту общего объема справочных данных, размер каждой отдельной БД может поддерживаться в разумных границах за счет образования новых доменов и связанных с ними новых баз данных. При необходимости повышения производительности и надежности в каждом домене может быть применено резервирование.
Коренным недостатком декомпозиционного подхода является то, что из-за изолированности справочных служб доменов пользователи и приложения получают удобный доступ к справочной информации только в пределах своего домена. В отсутствие какого-либо механизма объединения доменов пользователю придется самому решать, где может находиться искомая информация и по какому адресу следует посылать запрос. Понятно, что такой способ организации справочной службы в виде нескольких не связанных между собой справочных служб отдельных доменов нельзя признать эффективным.
Распределенная модель предполагает наличие нескольких физически разделенных баз данных, виртуально представленных для клиентов в виде единой центральной базы данных (рис. 5.8). В данном случае виртуализация означает, что пользователь любого домена может получить информацию о любом объекте сети вне зависимости от того, с какой рабочей станции поступил запрос и где находится требуемая информация. Такая справочная служба должна скрывать от пользователей различные физические параметры сети: местонахождение серверов, применяемые коммуникационные протоколы, маршруты перемещения запросов, характеристики коммуникационного оборудования и др.
Существуют различные механизмы связывания доменных справочных служб в единую службу сети. Например, в справочной службе Active Directory компании Microsoft таким механизмом является глобальный каталог (global catalog), схему применения которого иллюстрирует рис. 5.8.
 1
1
Рис. 5.8. Схема распределенной справочной службы
В то время как доменные базы данных содержат полную информацию об объектах одного домена, в глобальном каталоге представлена частичная информация об объектах всех доменов сети.
В качестве обязательной информации глобальный каталог хранит для каждого объекта атрибуты, которые указывают на местонахождение полной информации о данном объекте.
Копии глобального каталога размещают на сервере справочной службы в каждом домене. При поступлении запроса пользователя к ресурсам, находящимся вне его домена, справочная служба, пользуясь информацией из локальной копии глобального каталога, переадресует запрос к базе данных того домена, где находится интересующий пользователя объект. Все эти действия скрыты от пользователей справочной службы и выполняются автоматически.
Распределенная организация справочной службы является наиболее эффективной для крупных сетей. К числу ее достоинств можно отнести следующие:
Удобство доступа пользователей к справочной информации. В распределенной системе для пользователя поддерживается иллюзия единого централизованного хранилища всей информации, когда степень сложности доступа к любому объекту сети не зависит от того, с какого компьютера поступил запрос.
Удобство администрирования. Для каждой части распределенной базы данных, например домена, можно назначить отдельного администратора и наделить его правами доступа только к части информации обо всей системе.
Надежность. Распределенная система по определению имеет несколько хранилищ и центров обработки информации, а значит, при отказе одного из них система может продолжать функционирование, возможно, в ограниченном объеме. Кроме того, надежность может быть повышена за счет поддержания в каждом домене нескольких копий баз данных этого домена. Необходимые для этого процедуры согласования копий требуют значительно меньщих затрат, чем в централизованных системах, так как проводятся в пределах домена, а не всей сети.
Высокая производительность. Разделение данных между несколькими серверами снижает нагрузку на каждый сервер. Количество серверов не ограничивается числом доменов, так как в каждом домене могут быть установлены серверы, поддерживающие копии доменных БД. Повышению производительности может также способствовать приближение баз данных к источникам запросов за счет рационального разбиения сети на домены.
Хорошая масштабируемость. Распределенная служба продолжает эффективно функционировать даже в очень крупных сетях за счет возможности логической декомпозиции сети на домены. Это, в частности, позволяет ограничить объем БД, снизить вычислительные затраты на поддержание копий БД, приблизить серверы к клиентам, уменьшить сетевой трафик, ускорить время выполнения запросов.
Справочная служба Microsoft Active Directory
Как и большая часть справочных служб Active Directory компании Microsoft используется для решения задач аутентификации и авторизации пользователей сети.
Домены Active Directory
Домены являются основными элементами логической структуры Active Directory. В каждом из доменов реализуется централизованная справочная служба. Будучи связаны логически, службы доменов образуют распределенную справочную службу сети.
Справочная служба построена по архитектуре клиент-сервер. Клиентские компоненты, устанавливаемые на всех компьютерах сети, передают запросы к серверам справочной службы, которые в Active Directory называются контроллерами домена (Domain Controllers, DC). В каждом домене должен присутствовать хотя бы один контроллер домена. Он поддерживает доменную базу данных, то есть БД о пользователях и ресурсах того домена, в котором установлен этот контроллер. Контроллер домена также занимается аутентификацией пользователей при их логическом входе.
Местоположение каждого контроллера домена администратор выбирает в ходе проектирования сети. Географическое разнесение серверов позволяет обеспечить приближенность информации к источникам запросов. Любой компьютер в сети, будь то контроллер домена, рядовой сервер или рабочая станция, может быть присоединен только к одному домену.
Решение о том, на сколько доменов разделить сеть, принимается с учетом различных факторов. Прежде всего, учитывается, что домен является единицей администрирования. По умолчанию при создании домена права и разрешения, которыми наделяются администраторы и пользователи, распространяются только на этот домен. А для того чтобы пользователь (в том числе администратор) одного домена мог получить доступ к ресурсам другого домена, должны быть выполнены дополнительные административные действия. Таким образом, разделение сети на домены является наиболее надежным и наиболее естественным способом разделения зон ответственности между несколькими администраторами.
Для повышения надежности и производительности в домене устанавливается несколько равнозначных контроллеров домена, которые поддерживают несколько идентичных копий доменной базы данных. Процедура динамического копирования всех изменений, происходящих на каждом из контроллеров, на все оставшиеся контроллеры домена называется репликацией. Таким образом, домен является единицей репликации, то есть определяет часть сети, в пределах которой происходит репликация базы данных домена.
Каждый домен Active Directory является также доменом DNS-имен.
Объекты
Информация в справочной базе данных Active Directory представлена в виде иерархически организованного набора объектов, соответствующих пользователям, группам пользователей, компьютерам, принтерам, разделяемым папкам, элементам структуры (доменам и организационным единицам), конфигурационным параметрам и другим сетевым ресурсам. Объекты могут создаваться как «вручную» администратором, который использует для этой цели диалоговые средства Active Directory, так и автоматически службой Active Directory.
Объект уникально идентифицируется своим именем и представляет собой набор значений атрибутов, которые свойственны данному классу объектов.
Класс объектов — это формальное описание множества объектов, имеющих сходную природу и вследствие этого характеризуемых одним и тем же набором обязательных и необязательных атрибутов.
Соотношение между классом объектов и объектом примерно такое же, как между переменной и ее значением. Атрибуты, определенные для класса объектов, принимают разные значения для разных объектов.
Из определения класса объектов следует, что объекты, содержащие информацию о компьютерах, относятся к одному классу объектов, а объекты, представляющие принтеры, — к другому. Рассмотрим, например, стандартный для Active Directory класс объектов user. С этим классом объектов связан обширный набор атрибутов, которыми может быть представлена информация о пользователях. В число семи обязательных атрибутов объектов этого класса входит, в частности, каноническое имя пользователя, а номер телефона является примером одного из 250 возможных необязательных атрибутов.
Когда администратор регистрирует нового пользователя, в базе данных Active Directory для этого пользователя создается учетная запись (объект), в которой для всех обязательных и для некоторых необязательных атрибутов устанавливаются определенные значения. Например, регистрируя в качестве пользователя некую Полину, администратор определяет значение канонического имени пользователя (обязательного атрибута) — Polina, и значение номера телефона (необязательного атрибута) — 22345777. Таким образом, появляется новый объект класса user.
Глобальный каталог
Задача распределенной справочной службы состоит в предоставлении клиентам контролируемого доступа ко всем объектам сети, даже если источник запроса и запрашиваемый ресурс находятся в разных доменах.
Для решения этой задачи используется глобальный каталог. Как было сказано ранее в глобальном каталоге каждый объект представлен в виде «усеченной» версии, которая, как минимум, должна содержать атрибут, указывающий на местонахождение полной версии объекта. Такого рода атрибутом для большинства объектов Active Directory является отличительное имя (Distinguished Name, DN), которое однозначно в пределах всей сети идентифицирует объект. Это имя подобно полному составному символьному имени файла в иерархической файловой системе, только в нем вместо имен каталогов указываются имена доменов и других узлов иерархической структуры базы данных объектов. Средства пользовательского интерфейса позволяют пользователю обращаться к объекту по его краткому имени — относительному отличительному имени. В этом случае служба Active Directory сама дополняет его до полного имени, используя контекстную информацию. Аналогично поиску файлов в файловой системе, поиск объекта может осуществляться и по значению какого-либо его атрибута. Например, чтобы найти объект класса user, клиент справочной службы может указать каноническое имя пользователя или адрес его электронной почты, а при поиске принтера — его тип. В этом случае Active Directory может вернуть клиенту информацию о нескольких объектах, каждый из которых удовлетворяет запросу, давая возможность пользователю самостоятельно выбрать интересующий его объект. Информация в главном каталоге позволяет определить DNS-имя контроллера, в котором хранится объект. На основании этого имени система DNS определяет IP-адрес контроллера, после чего задачу доступа к требуемому объекту можно считать решенной.
Глобальный каталога используется также для решения еще одной важнейшей задачи справочной службы — глобальной аутентификации и авторизации[2] пользователей. Слово «глобальная» в данном случае означает, что пользователь при определенных условиях может выполнять логический вход в сеть с любого компьютера любого домена сети. Такая принципиальная возможность появляется благодаря тому, что в глобальном каталоге хранится информация об универсальных группах пользователей, в которые могут включаться члены разных доменов. Например, если сотруднику некоторого предприятия в Томске, оказавшемуся в командировке в барнаульском отделении, потребовалось выполнить некоторую работу на компьютере, то он может войти в сеть с любого компьютера сети предприятия в Барнауле независимо от того, относятся ли сети в Томске и Барнауле к одному и тому же домену или нет. Набрав идентификатор и пароль, полученные при регистрации от администратора в томском отделении, командированный сотрудник получает доступ к ресурсам сети в соответствии с теми же правами и разрешениями, которые он имел, входя в сеть со своего рабочего компьютера в Томске.
Иерархия организационных единиц Active Directory
Как и все современные справочные службы, Active Directory является иерархически организованной системой. Иерархия логически упорядочивает информацию о многочисленных объектах, дает возможность «увидеть» всю систему в целом, упрощает процесс именования объектов и делает более эффективным выполнение индивидуальных и групповых действий над ними, таких как поиск, удаление, изменение свойств и т. д. Основными строительными блоками иерархической структуры являются домены и организационные единицы.
Организационная единица (OU) — это специфический объект Active Directory, который представляет группу объектов, объединенных в соответствии с теми или иными их свойствами.
Если таким свойством является, например, тип объектов, то организационные единицы могут представлять собой группы пользователей, компьютеров или принтеров. Территориальная общность или принадлежность к одному и тому же подразделению также может быть использована для группирования объектов в организационные единицы, например: OU филиала предприятия в Москве и OU филиала в Перми, OU рекламного отдела, OU отдела перспективных разработок.
Организационные единицы, используемые исключительно с целью группирования других объектов, называются контейнерами (container). В этом случае оказывается полезной аналогия с файловой системой, в которой каталоги могут рассматриваться как контейнеры, содержащие внутри себя логически сгруппированные файлы.
Организационные единицы не только являются логической группой объектов, но и сами могут быть включены в другие организационные единицы. Группируя таким образом OU, можно образовывать древовидные структуры (OU-деревья), подобные древовидным структурам файловой системы. В Active Directory для каждого из доменов строится отдельное OU-дерево. В качестве корня в OU-дереве выступает не организационная единица, а объект, соответствующий домену, для которого построено это дерево. OU-дерево, показанное на рис. 5.9, включает два уровня организационных единиц. На верхнем уровне расположены OU офиса предприятия в Москве и OU центрального отделения в Барнауле. В каждую из этих организационных единиц входит еще по две организационные единицы: computers и users для московского офиса user и hardware для отделения в Барнауле.

Рис. 5.9. OU-дерево
Иерархическое структурирование объектов позволяет эффективно выполнять групповые операции (переименование, уничтожение, определение правил доступа и т. п.) сразу для нескольких объектов, представленных как отдельной организационной единицей, так и ветвью OU-дерева, а также делегировать администрирование отдельными объектами и ветвями OU-дерева другим администраторам. В примере на рисунке для каждого из двух подразделений предприятия администратором была создана отдельная ветвь OU-дерева, что дает возможность назначить для этих двух подразделений, находящихся в разных часовых поясах, двух разных администраторов, которые смогут более эффективно управлять пользователями и ресурсами, относящимися к этим структурным единицам. В частности, локальным администраторам может быть передано право создавать пользовательские учетные записи, переустанавливать пароли и выполнять другие действия, которые проще выполнять в непосредственной близости к пользователям.
Иерархия доменов. Доверительные отношения
Домены являются более независимыми структурными единицами, чем организационные единицы внутри домена. В частности, именно пределами домена, а не OU, ограничиваются действие политики паролей (password policies), устанавливающей длину и другие параметры паролей пользователей, и действие политики блокировки учетных записей (account lockout policies), определяющей функции администратора в тех случаях, когда пользователь забыл или не смог правильно набрать свой пароль и его учетная запись была заблокирована. Разграничение функций по администрированию на уровне доменов происходит очень естественно благодаря тому, что каждый домен имеет встроенные группы Administrators и Server Operators, членам которых разрешено совместно использовать папки и форматировать диски только на контроллерах своего домена.
Такие свойства доменов делают привлекательной идею представления сети в виде нескольких доменов. Наиболее часто используемой многодоменной структурой является дерево доменов (рис. 5.10).

Рис. 5.10. Дерево доменов
На рисунке показано трехуровневое дерево доменов. Каждый домен условно изображен в виде треугольника. Упорядочение доменов по уровням иерархии происходит аналогично упорядочиванию каталогов файловой системы. Первый по времени создания домен становится корнем дерева. Для следующего создаваемого домена, называемого потомком, корневой домен является родительским и т. д. Иерархические отношения между доменами выражаются в том числе и в их именовании. Корневому домену при его создании присваивается DNS-имя, пусть это будет, например, company.ru (рис. 5.11). Все домены-потомки получают «в наследство» имя родительского домена, которое добавляется к их собственным именам, образуя DNS-имена следующего уровня.
Между каждым новым доменом-потомком и его родительским доменом автоматически устанавливаются так называемые доверительные отношения. Установление доверительных отношений включает передачу части доменного справочника присоединяемого домена в глобальный каталог родительского домена, после чего он становится общим для всего дерева доменов. Глобальный каталог создается автоматически во время установки первого контроллера в первом домене сети. Первоначально в главном каталоге размещается полная копия всех объектов, относящихся к этому первому домену. В результате создания новых доменов к главному каталогу прибавляются частичные копии баз данных каждого из этих доменов. Эти копии содержат атрибуты объектов, позволяющие определить местонахождение соответствующих объектов, а значит, дающие пользователям возможность получать доступ к объектам не только своих, но и других доменов.
Для обеспечения безопасности в процедуру установления доверительных отношений вовлечена система аутентификации Kerberos[3].
Установление доверительных отношений между двумя доменами дает возможность:
- пользователю (или группе пользователей) одного домена получать доступ к ресурсам другого домена (это означает, что нет необходимости создавать две учетные записи в этих двух доменах для одного и того же пользователя);
- администрировать один домен из другого домена, для чего необходимо включить в группу пользователей, наделенную правами администрирования домена, пользователей из другого домена.
В Active Directory доверительные отношения, устанавливаемые по умолчанию между родительским доменом и доменом-потомком, являются транзитивными и двусторонними.
Отношения транзитивны, если из того, что А доверяет В, а В доверяет С, автоматически следует, что А доверяет С. Отношения являются двусторонними, если из того, что А доверяет В, следует, что В доверяет А.
Отсюда следует, что все домены дерева связаны друг с другом двусторонними транзитивными доверительными отношениями.
Active Directory может иметь и более сложную доменную структуру, состоящую из нескольких деревьев, называемую лесом (рис. 5.12). Все домены леса так же, как и домены дерева, связаны двусторонними транзитивными доверительными отношениями, то есть имеют общий глобальный каталог. Следовательно, пользователи сети, имеющей доменную структуру в виде леса, могут быть наделены правом доступа к любым ресурсам любого домена.

Рис. 5.12. Лес доменов
Еше одной доменной структурой, используемой в Active Directory, является модель множественных лесов. Эта модель может оказаться полезной для крупных транснациональных корпораций, образованных в результате слияния нескольких предприятий, а также в случаях, когда организация представляет собой объединение нескольких крупных и достаточно независимых подразделений. Являясь наиболее децентрализованной структурой, модель множественных лесов состоит из нескольких изначально совершенно не связанных между собой лесов. Между доменами разных лесов могут быть установлены контролируемые администратором доверительные отношения, однако это происходит не автоматически, как при построении деревьев и лесов, а в результате некоторых дополнительных действий администратора.
Контроллеры доменов Active Directory могут отличаться друг от друга набором предоставляемых услуг. Для того чтобы пользователи и приложения могли находить именно те контроллеры, на которых установлены необходимые им сервисные программные модули, контроллеры регистрируют имена своих сервисов в системе DNS, которая по запросам клиентов сообщает им о местонахождении (IP-адресах) серверов и сервисных программ Active Directory. В некоторых случаях система DNS может вернуть IP-адреса нескольких контроллеров, предоставляющих эту услугу. Используя дополнительную информацию о месте расположения контроллеров, клиентская станция выбирает ближайший к ней контроллер.